记一次生产环境Nginx间歇性502的事故分析过程
最近我们我们在将部分业务从自有机房迁移到国内某云服务器上,在小规模上量后,发现Nginx间接性出现大量502。异常出现的特点是,一瞬间后端多个独立部署的服务全部出现502。
我们的服务架构如下:
1 | +--------+ HTTP +-------+ HTTP +-------+ |
一般讲,Nginx 502就是后端处理不过来,但查看监控后端几个API的负载均很低,当前请求的QPS远远低于服务的上限。而且同一瞬间,多套独立部署的API均处理不过来的概率也比较低。
我们简单做了个对比测试,分别对域名(请求走Nginx)与直接通过IP对内网一个API通过wrk进行小规模压测。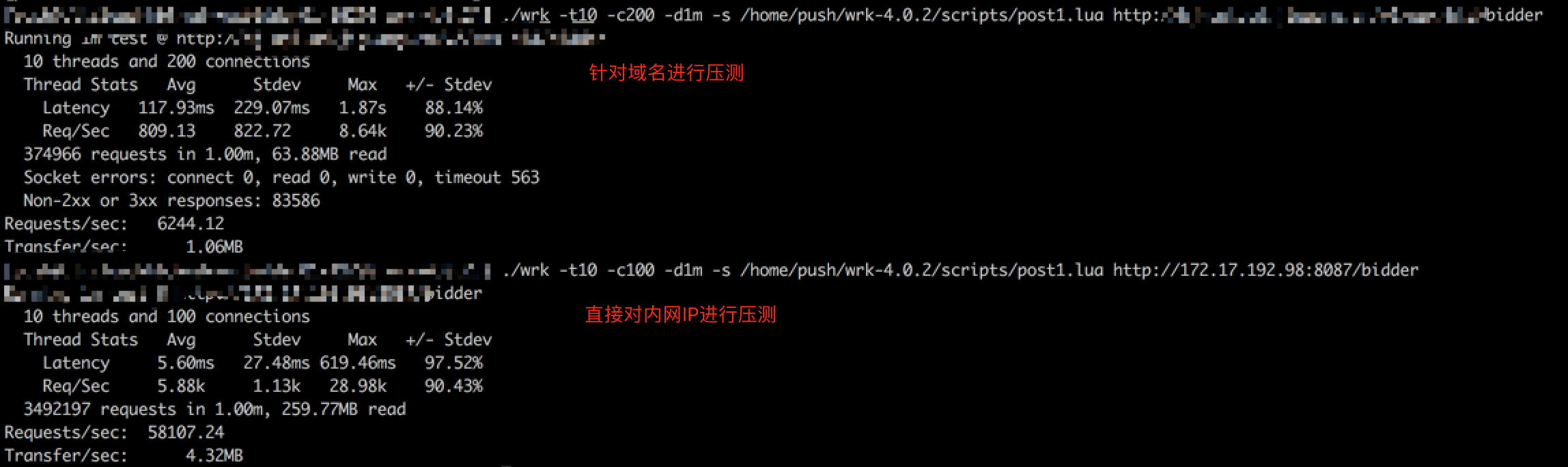
对比测试发现,直接通过域名走Nginx对API进行压测的话,QPS远远小于预期,并且存在大量失败请求。基本断定问题出在Nginx —> API 这条链路上。同时排除了后端服务响应不过来的可能性。网络问题可能性大一点。
一开始我们怀疑云服务商对内网带宽做了限制,我们观察内网带宽达到在200MB/S后就上不去了,所以我们在Nginx机器上ping后端服务,观察一段时间发现有小量抖动,但基本延迟正常。那云服务商对网络做限制的可能性就变小了很多。
我们观察Nginx错误日志:
1 | 2017/09/26 14:23:00 [error] 4950#4950: *4162133210 no live upstreams while connecting to upstream, client: xxx.xxx.xxx.xxx, server: api.xx.xxxxxxx.cn, request: "POST /xx/xxxxxx/bidder HTTP/1.1", upstream: "http://xxxxxxxxxx/bidder", host: "api.xx.xxxxxxx.cn" |
这里出现no live upstreams while connecting to upstream, 也就说一瞬间Nginx检测不到任何存活的后端服务,而网络又没有大波动,那就可能是TCP链接出问题。打开Zabbix监控发现TCP连接数的确发生剧烈的波动现象。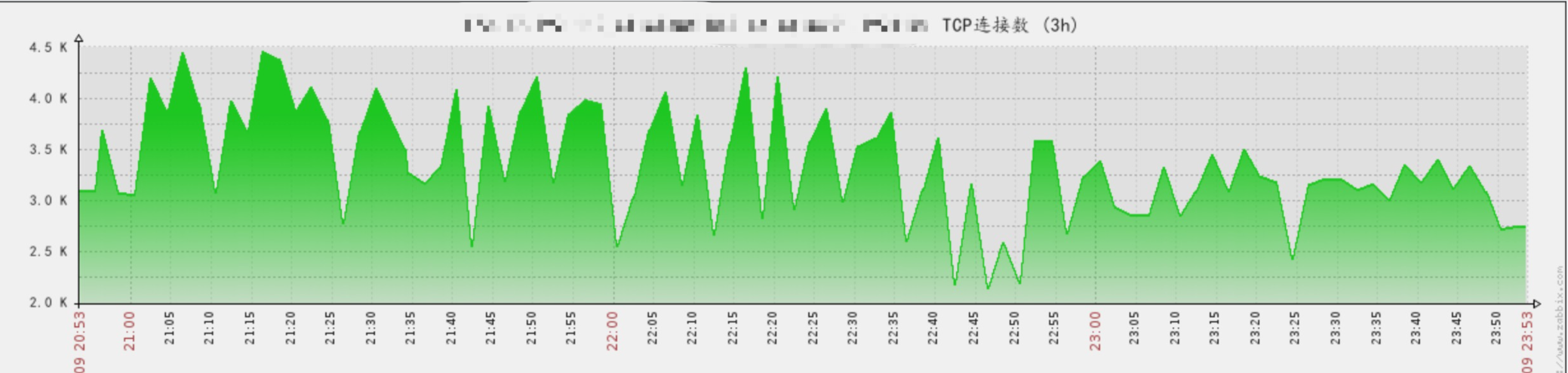
这时候问题很明显,Nginx->API这一链路存在大量的TCP链接被回收的情况,我们马上在API机器上查看链接状态
1 | shell > netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}' |
TIME_WAIT特别的多,大量的连接被API侧主动关闭了。这说明Nginx->API这一步请求并没有Keep-Alive,我们检查Nginx,确定是配置了Keep-Alive
1 | upstream xxxxxxx { |
因为业务的特殊性,我们很确定Client一定为携带Keep-Alive的。那么说明后端API没正确的支持Keep-Alive,我们开始对API代码逻辑进行Review,但我们检查配置,发现服务默认是开启Keep-Alive的,我们进行显式的配置,仍然不起作用。这里存在一个可能性就是我们时候的Web框架有BUG。所以我们接下来做了一个测试,来验证服务是否开启了Keep-Alive。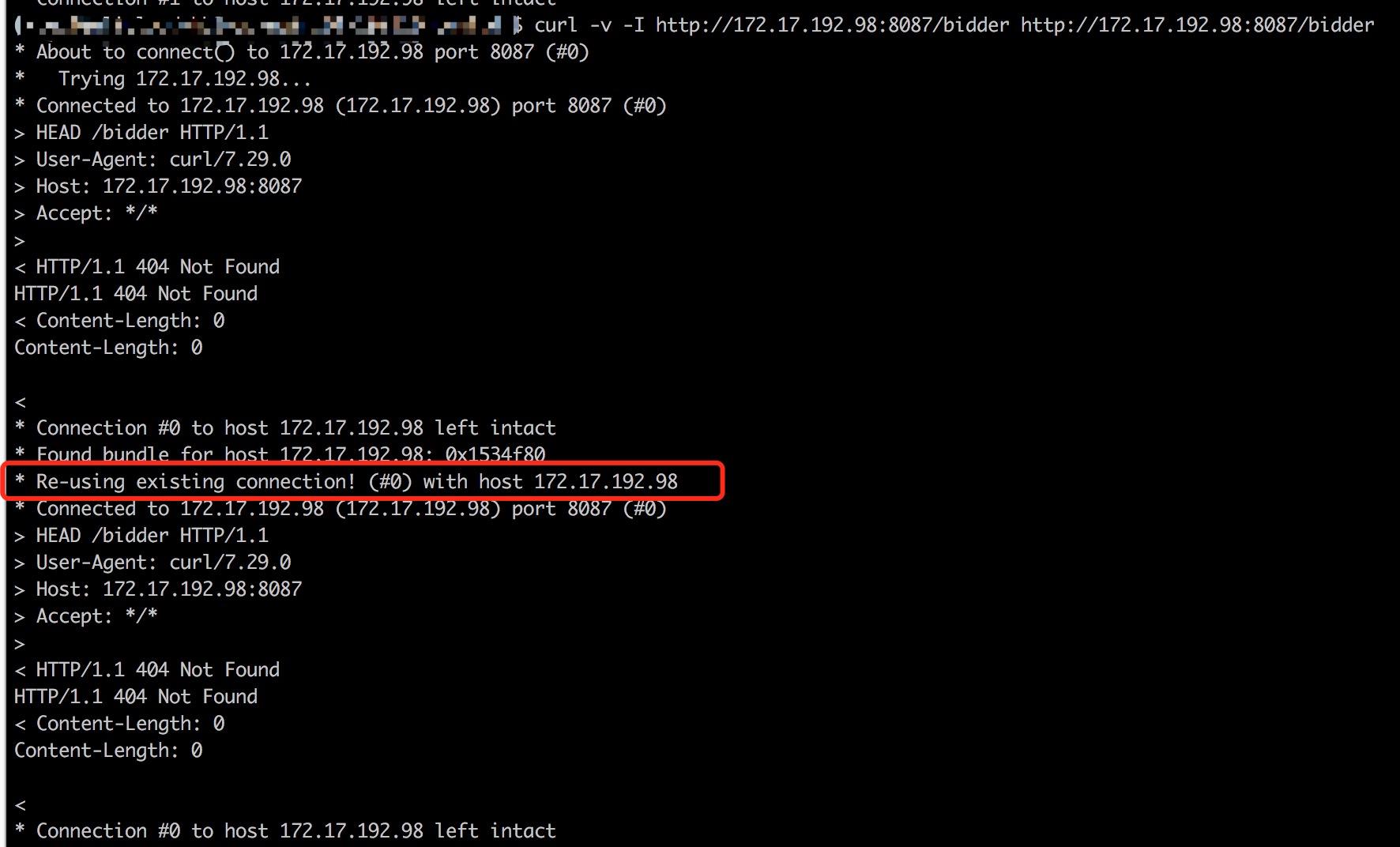
我们使用curl连发两次请求,在第二次请求的报文中,我们可以看到Re-using existing connection。这说明连接被复用,后端API服务对Keep-Alive的支持是正常的。
这时候就陷入了困境了,求助Google大神后,发现Nginx支持Keep-Alive还需要在配置转发的时候的时候增加以下配置:
1 | location ^~ /xxxxx/ { |
贴上配置后,惊奇的发现问题解决了,后端服务器TIME_WAIT的链接下降到2位数,并且也不再出现502现象。棒!
后续发展
在HTTP 1.0中,Keep-Alive默认是关闭的,需要在请求头显式加上Connection: Keep-Alive,才能启用Keep-Alive。但在HTTP 1.1中,该功能默认是开启的,需要使用Connection: Close才会禁用Keep-Alive。目前大部分浏览器都是使用HTTP 1.1协议。
我们后来分析所有的Client请求,发现全部都是1.1协议,这就很诡异了。接下来我们在Nginx->API这条链路上捉包,惊奇的发现,竟然出现部分流量是1.0协议的,部分是1.1协议的。这里就解释了为什么会出现连接无法复用的问题。所以我们统一将所有的转发配置都增加了以下规制强制指定使用1.1协议。
1 | location ^~ /xxxxxx/ { |
但整个事故中,仍然存在几个疑点:
- 为什么Nginx转发的流量中,会混入1.0协议的请求呢?
- 是什么原因导致Nginx或Nginx所在服务器的操作系统在对TCP链接大量回收,并且把正常连接也回收掉导致后端Server “no live upstreams”了呢?
目前暂无头绪,后续分析有结果再补上。