Redis Cluster 初探(2) - 运行规制
上一篇文章我们说过,Redis Cluster 采用Smart Client的方式,避免与节点的通讯还需要通过一层Proxy,以达到性能地提升。 Smart Client的优点与缺点网上也有很多人在讨论,我们现在来了解下Redis Client的运行规制。
Redis Cluster是无中心节点的设计,Client可以连接集群中的任一一个节点,当操作的Key不在该节点的Slot中的时候,如访问在Slot-6433的Key,客户端会返回一个 (error) MOVED 6433 10.211.55.4:7001 这样的错误信息。Client捕获到此异常后,再自动重定向到 10.211.55.4:7001 这个节点上并获取数据。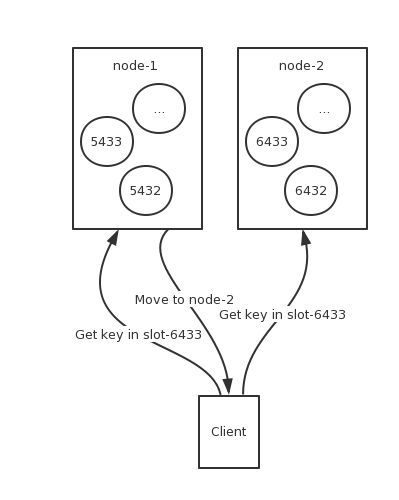
虽然每次请求客户端都会重新定向,但这样额外耗费多一次连接是很没有必要的,官方建议在初次建立连接后,Redis Client会获取连接集群的节点信息以及Slot分布信息,并在本地缓存一份hash slot与node关系的的路由表,当收到操作请求时,先本地用CRC16算法计算出该Key对应哪一个Slot,再在表中查询该Slot的节点信息,最后选择对应的节点去连接,这样,每次请求就不需要通过一个统一的代理层去转发请求。当服务器进行扩容,迁移数据的时候,客户端的路由表并不会立即更新,而是当在被迁移是Slot上操作的时候,因为Slot已经不在原先的节点上了,Redis Cluster返回Moved指令,告诉客户端该Slot现在所在的节点。此时,客户端应该更新自己的路由表信息,以达到最优,即每次操作直接与节点通讯并不进行跳转。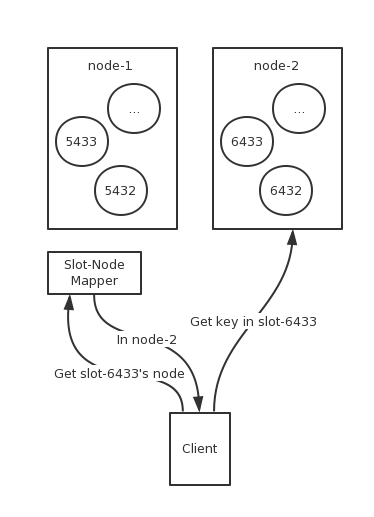
在前面我说道过,Redis Cluster预先将Key分到16384个Slot,通过CRC16算法算出Key该被分配到哪一个Slot中。
1 | HASH_SLOT = CRC16(key) mod 16384 |
但是这么做有一个缺陷就是,如果你需要进行涉及多个key的操作的话,因为Key可能被分散到不同的节点中,所以查询请求将会在各个节点间跳转,效率会非常差,为此,Redis Cluster干脆不支持所有的多Key操作命令。
假如你想使用多Key操作命令,可以通过Keys Hash Tag去将相关数据强制存储在同一个slot。当一个key包含{和}的时候,Redis-Cluster会取{和}之间的字符进行CRC16哈希算出存放在哪个slot,比如:
{user1000}.following这个key会使用user1000的hash值foo{}{bar}这个key会使用foo{}{bar}的hash值,因为第一个{和}之间的值为空foo{{bar}}zap这个key会使用{bar的hash值foo{bar}{zap}这个key会使用{bar}的hash值
但是使用Hash Tag仍然仍然会面临新的问题,因为不可避免会有些Key的Value额外的大,虽然根据概率学,当基数足够大的时候,每一个Slot的大小都会趋于平均,但实际应用中,我使用我们生产环境的一些数据进行测试,Cluster节点数目为16,测试数据集大概16G,存储数据结构为Set,每一个Key对应一个或多个Value,正常来说最终测试结果每一个节点的内存占用应该为1G,但实际上,内存使用最高与最低相差足足有200M。
在集群运行的过程中,不可避免有些节点会因为各种原因挂掉(被踢掉网线,打雷,停电,软件故障>_>)。所以,在成本允许范围内,我们会尽量避免所有节点在同一台物理机上,避免Master,Slave在同一台物理机上,利用Redis Cluster的自动故障转移的功能,让集群在及时部分节点挂掉的情况下,仍然能继续工作。
为了数据的安全性,我们一般会保持一份及以上的数据冗余。即一个Master节点对应多个Slave节点模式,当Master节点挂掉后,集群自动选择一个Slave升级为Master节点,重启原Master节点并作为Slave节点加入现有集群。
而Redis Cluster是如何发现节点挂掉呢?在集群中,每一个节点之间都会保持一个长连接,即有N个节点的集群,每个节点将会保持N-1条长连接,节点定时给其他节点发送Ping指定,如果在指定的timeout内没有返回Pong,即认为该节点故障,并启动故障转移。节点timeout的时间是可以配置,但是需要明白的是,当一个节点故障的时候,他通常不能写入数据并且不能读取数据,所以节点故障到其他节点发现其故障并且进行故障转移这段时间内,写入该节点的数据可能会丢失。所以timeout时间过长意味着你将在节点故障的时候丢书过多的数据,而timeout时间过短则可能引发误判。
当一个Master节点以及他的所有Slave节点都挂掉的时候,集群将处于不可用的状态,当然这是可以配置的。我们可以根据业务来决定是否打开此开关。
坑
Redis在实际应用中的一些需要避免的一些坑,在Redis Cluster之中同样存在,在调研Redis Cluster与我实际测试中,总结一些别人遇到以及我自己掉入的坑。
为什么Redis需要预留额外一半的内存?因为Redis的AOF实际上是通过fork一个Redis进程来实现,所以为了防止AOF集中发生,出现SWAP和OOM,所以需要预留额外的一半内存。但实际有更优的解决办法:
- 关闭Redis所有自动落地,通过一个Remote控制中心来管理Redis实例,远程调用
BGSAVE命令主动触发落地。避免同一时间落地导致内存不足。 - 设置最大内存使用,当内存超过此阀值的时候,写入将失败,但读取仍然是正常的,可以配置告警脚本。这能最大限度保证Redis进程不会因为内存过高而挂掉。
- 关闭Redis所有自动落地,通过一个Remote控制中心来管理Redis实例,远程调用
在云风的 谈谈陌陌争霸在数据库方面踩过的坑( Redis 篇) 中提到一个Redis的主从方案,即一个Master节点对应N个Slave节点,如果所有的节点都选择数据落地,每一台机器都需要预留很多内存来防止落地的时候的内存占用过高问题,但实际上这是很没有必要的,我们可以选择其中几个Slave节点进行数据落地即可。但这招在Redis Cluster是行不通的,因为Redis Cluster的故障迁移功能,默认是Master节点如果挂掉的话,Slave会自动升级为Master节点,原先的Master节点自动重启并作为Slave节点加入集群。这样如果我们在集群中指定其中几个Slave节点进行数据落地的话,当发生故障转移的时候,落地策略就会出现混乱。